ReturnX
Proof-of-Concept on reinforcement learning based Arbitrage Bot ( Cross-DEXes )
Screenshots


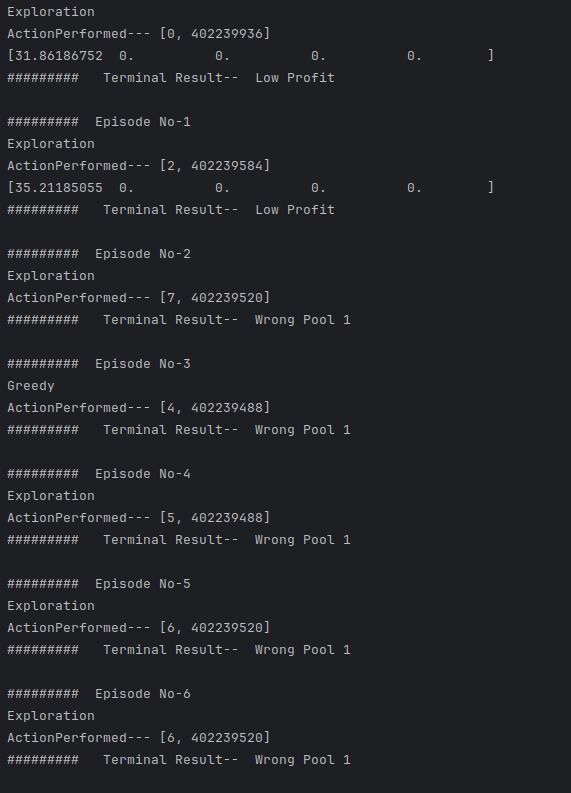
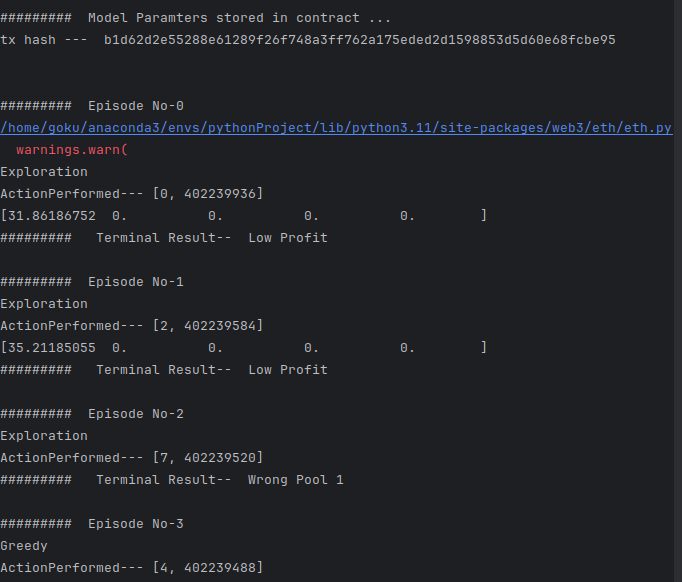
Problem Statement
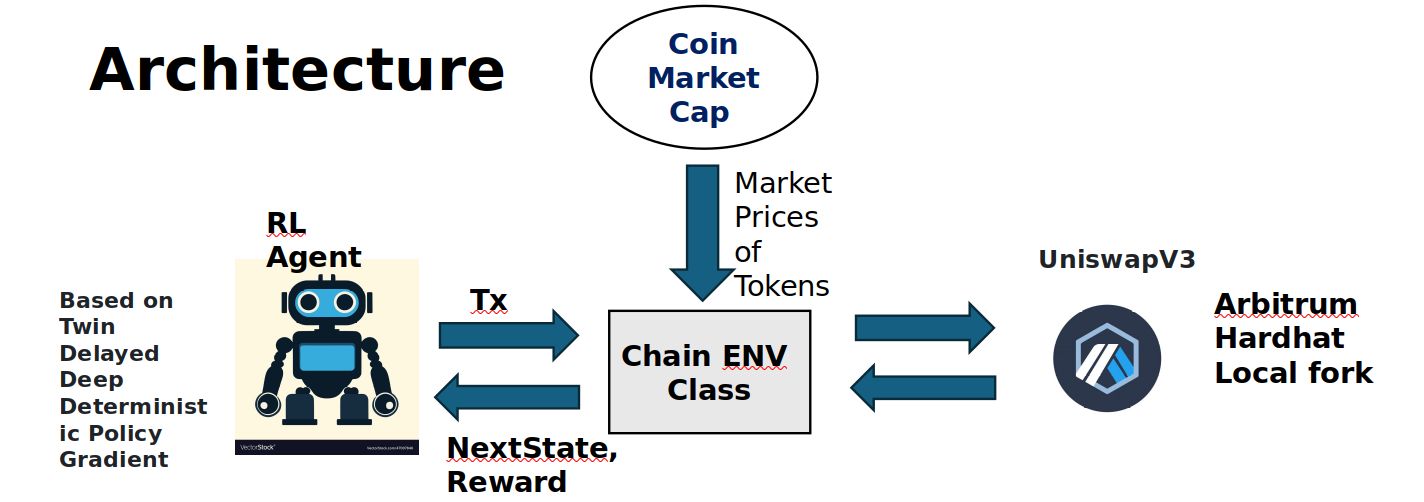
This project showcases a proof-of-concept for an automated trading system, "ReturnX," leveraging reinforcement learning techniques, specifically the Twin Delayed Deep Deterministic Policy Gradient (TD3 DDPG) model. The aim is to identify and capitalize on arbitrage opportunities across decentralized exchange (DEX) networks.The primary objective is to demonstrate the feasibility of utilizing reinforcement learning for automated trading across multiple DEX platforms. It's important to note that this project serves as a proof of concept, and the model used is not yet trained.Technical Details and Components: The project is structured into several components:Network and Agent Files: These files contain the implementation of the TD3 DDPG model, including the neural network architecture and the logic for making trading decisions.Train.py: This file houses the main training function responsible for training the reinforcement learning model. It iterates over multiple episodes, updating the model's parameters based on observed rewards and penalties.Utils.py: This module provides utility functions for plotting graphs and visualizing training progress, aiding in analyzing the model's performance.Config.ini: This configuration file stores addresses and other parameters necessary for the operation of the trading system, including contract addresses and API keys.ChainENV.py: Main class for submitting transactions on-chain, observing state changes, and generating required rewards and the next state.Future Directions: While the current focus is on demonstrating the feasibility of using reinforcement learning for automated trading, future iterations will involve training the model and expanding its capabilities. This includes refining the model's architecture, optimizing hyperparameters, and extending its reach to additional DEX platforms.
Solution
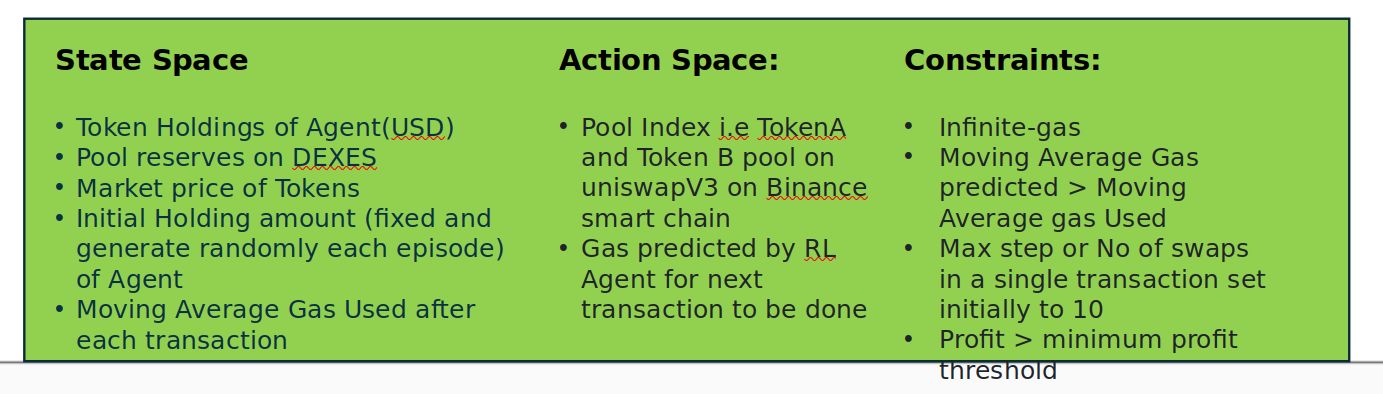
My tech stack consists of Python with Anaconda for package management, PyTorch for TD3 DDPG implementation, Web3.py for blockchain interaction, and UniswapV3 for decentralized exchange operations. Market prices of tokens are taken from CoinMarketCap.Technical DetailsReward Function: This defines how the agent is rewarded based on its actions and the state of the environment. Here are the conditions:profitThreshold: The minimum profit the agent should achieve. lpTerminalReward: Reward when the profit is low or negative. wpTerminalReward: Reward when no tokens exist in the pool. ngTerminalReward: Reward when less gas is used. stepLimit: The maximum number of steps (or swaps) allowed in an episode.Constraints: These are conditions that the agent must adhere to during training. They include:Infinite gas: The agent has an unlimited supply of gas. Moving Average Gas predicted > Moving Average Gas Used: The gas predicted to be used should be less than the gas actually used. Max step or Number of swaps in a single transaction: Limited to 10 swaps per transaction. Profit > profitThreshold: The profit should exceed the defined threshold.State Space: This describes the information available to the agent to make decisions. It includes:Token Holdings of the Agent (in USD) Pool reserves Market price Initial Amount (fixed each episode) Gas UsedAction Space: This defines the actions the agent can take. It consists of:PoolIndex: The index of the pool the agent wants to interact with. GasPredicted: The amount of gas predicted to be used in the transaction.To start training, you'll need to execute the train.py script. If you need to adjust the reward function, you can modify the step function in Agent/chainENV.py.
Hackathon
Scaling Ethereum 2024
2024
Prizes
- 🏆
Best dApp deployed on Avail - powered Rollup
Avail
- 🏆
Qualifying Arbitrum Submissions
Arbitrum
Contributors
- hardik-kansal
14 contributions
