Screenshots
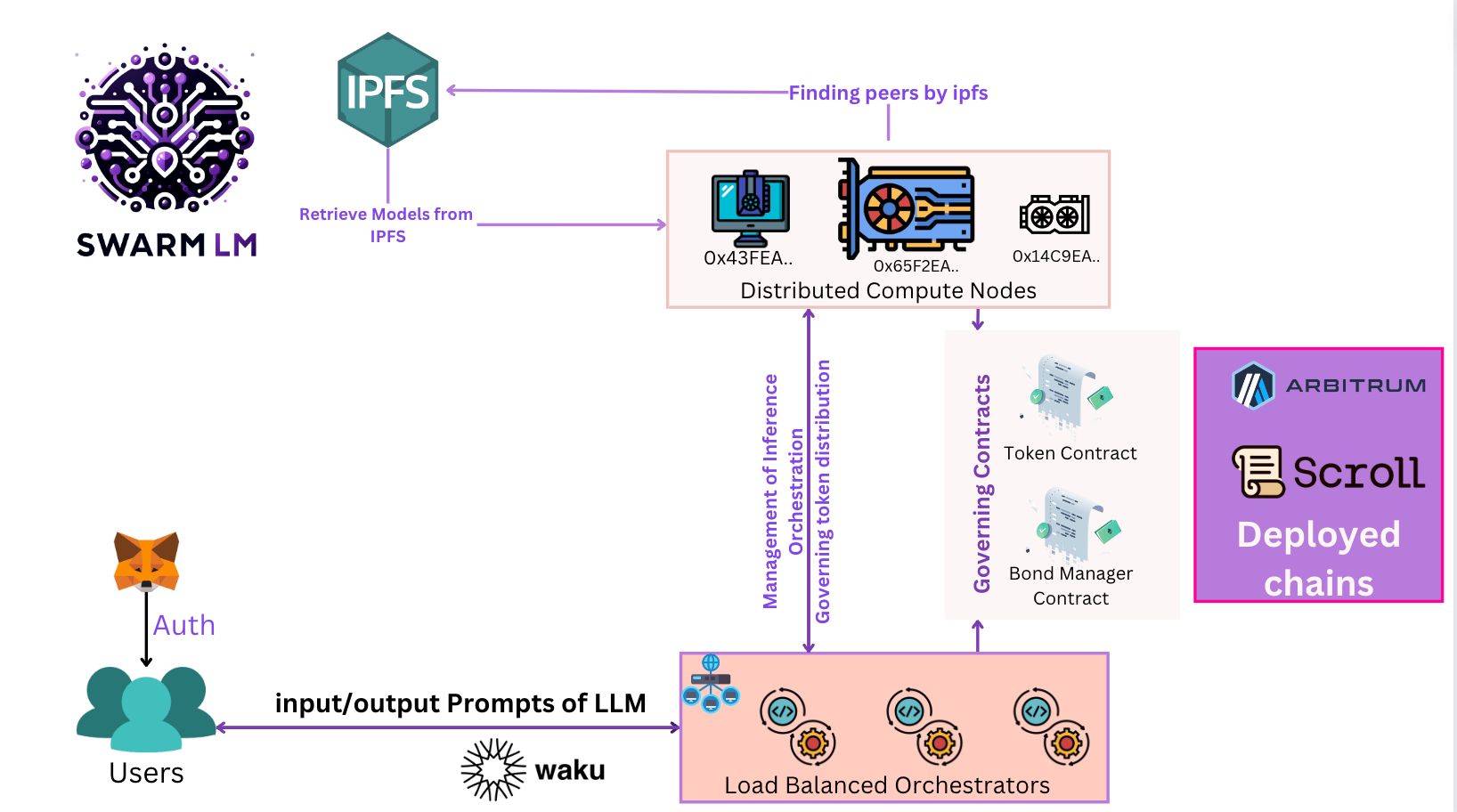
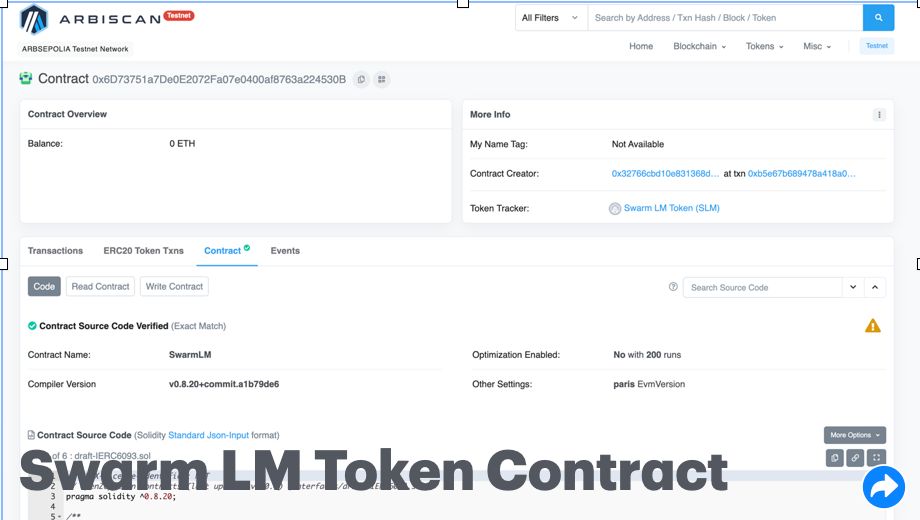
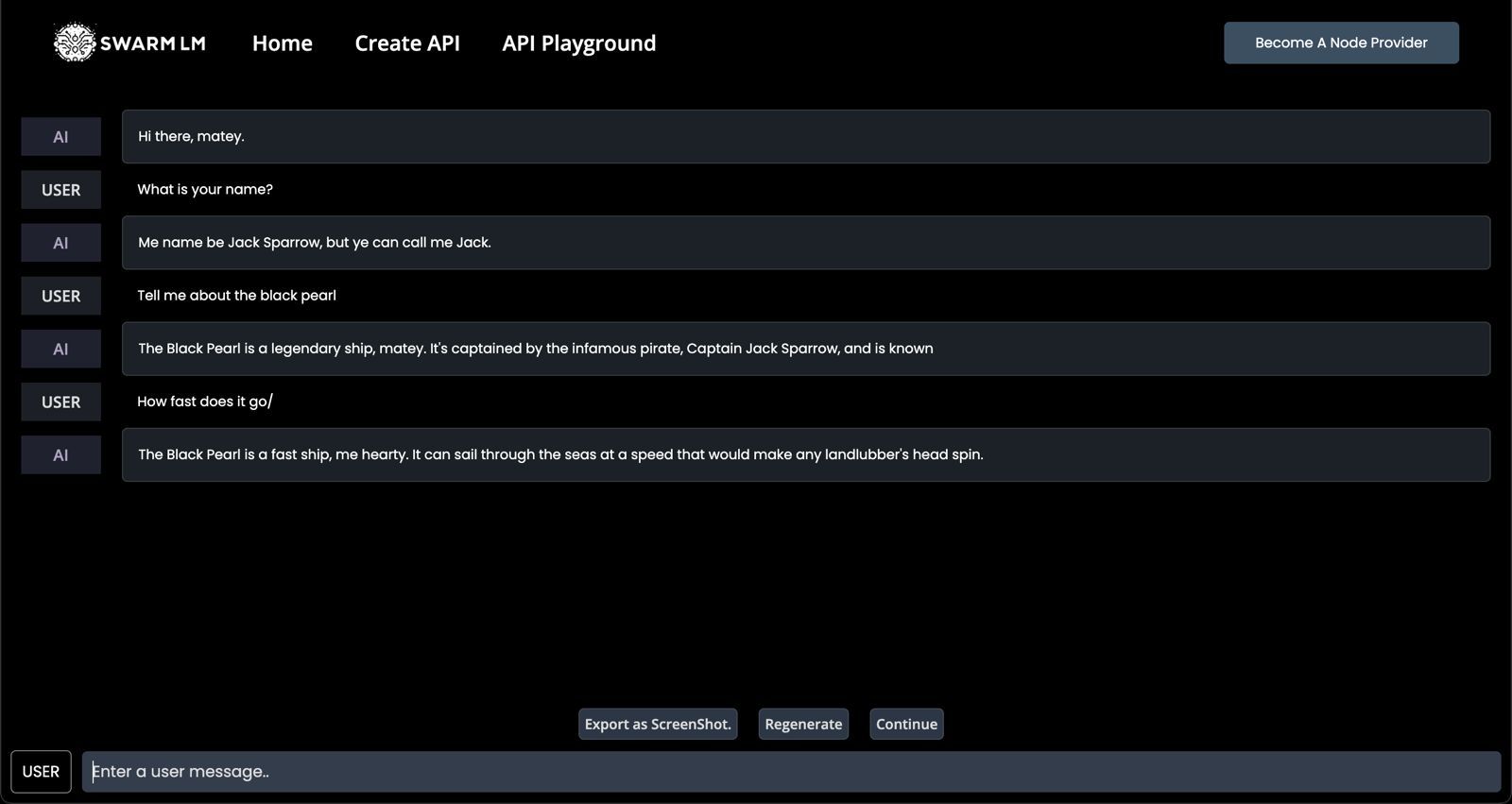
Problem Statement
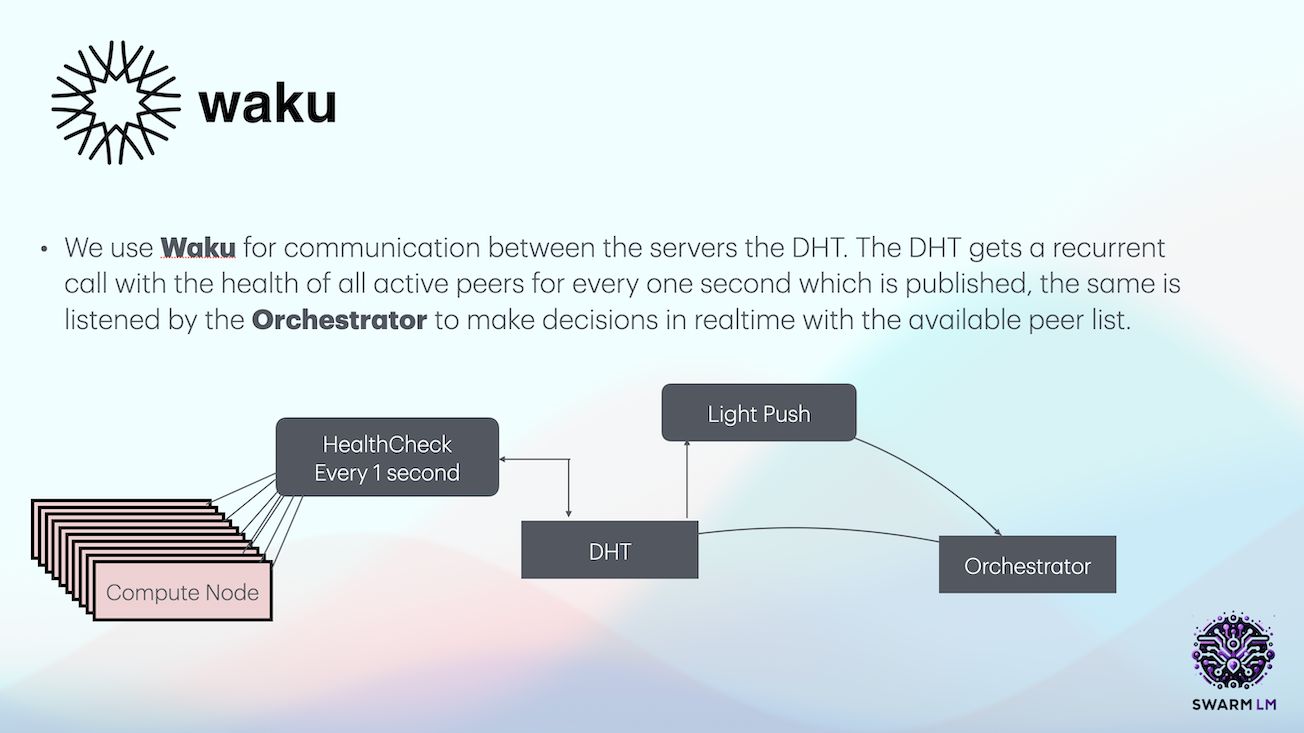
DillingerProblem statementRunning larger LLM’s with parameters over 30B requires huge infra thereby restricting research efforts.ChatGPT and other closed source platforms do not make the cut.SolutionDecentralised Inference for LLMs!SwarmLM introduces a decentralised approach to LLMS computation.The Transformer can infer layers of the model in a distributed compute environment.Clients (orchestrators) can create chains of pipeline-parallel servers (Compute Nodes) for distributed inference.This eliminates the need for a single massive resource (HPC) to run LLM models.SwarmLM incentivises contributors to dedicate resources and earn tokens through Proof of Compute.StakeholdersCompute Node Providers:GPU providers, Incentivised by Proof of Compute/Inference i.e. generation of token(LLM) volume.LLM Users:Research people/civilians who want to build and tune LLM’s on the fly without HPC infrastructure.Pledge token to Bond manager Contract, get API key to utilise the Decentralised inference Network.Linkshttps://swarm-lm.vercel.app/https://github.com/albyzyx/swarm-lm-nodehttps://github.com/albyzyx/swarm-lm-interfacehttps://github.com/albyzyx/swarm-lm-contractshttps://github.com/yedhukrrish/waku_node.git
Solution
Since the entire decentralization part is built atop of python and flask we faced major issues with respect to creating an interoperable space.
